| Дискретний рівномірний розподіл |
|---|
 Масова функція розподілу імовірностей для рівномірного розподілу із параметром n = 5
n = 5 де n = b − a + 1 |
Функція розподілу ймовірностей 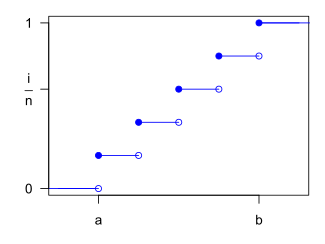 Кумулятивна функція дискретного рівномірного розподілу для n = 5 |
| Параметри | 

 |
|---|
| Носій функції |  |
|---|
| Розподіл імовірностей |  |
|---|
| Функція розподілу ймовірностей (cdf) |  |
|---|
| Середнє |  |
|---|
| Медіана | |
|---|
| Мода | N/A |
|---|
| Дисперсія |  |
|---|
| Коефіцієнт асиметрії |  |
|---|
| Коефіцієнт ексцесу |  |
|---|
| Ентропія |  |
|---|
| Твірна функція моментів (mgf) |  |
|---|
| Характеристична функція |  |
|---|
В теорії ймовірностей і статистиці випадкова величина має дискретний рівномірний розподіл, якщо вона приймає скінченне число значень з однаковими ймовірностями.
Якщо випадкова величина може приймати будь-яке з n значень k1,k2,…,kn, тоді це є дискретним рівномірним розподілом. Ймовірність випадання kj дорівнює 1/n. Простим прикладом дискретного рівномірного розподілу є випадання гральної кості. k набуває значень 1, 2, 3, 4, 5, 6 і кожен раз  випадає з імовірністю 1/6. У випадку, коли випадкова величина є дійсним числом, то функцію розподілу можна виразити у термінах виродженого розподілу таким чином:
випадає з імовірністю 1/6. У випадку, коли випадкова величина є дійсним числом, то функцію розподілу можна виразити у термінах виродженого розподілу таким чином:

Вибірка із k спостережень отримана із рівномірного розподілу цілих чисел  , для якої існує задача оцінити невідомий максимум N. Цю задачу іноді називають задачею про німецький танк[en], після того як цей метод оцінки максимуму було застосовано для оцінки темпів виробництва німецьких танків під час Другої світової війни.
, для якої існує задача оцінити невідомий максимум N. Цю задачу іноді називають задачею про німецький танк[en], після того як цей метод оцінки максимуму було застосовано для оцінки темпів виробництва німецьких танків під час Другої світової війни.
Незміщена оцінка з мінімальною дисперсією для рівномірного розподілу, яка визначає максимум задається наступним чином

де m є вибірковим максимумом, а k - розмір вибірки, для вибірки без повторного заміщення.[1] Цей приклад можна розглядати як спрощений випадок оцінки максимального інтервалу[en].
При цьому матимемо дисперсію[1]

тож стандартне відхилення приблизно становить  , середній розмір (для сукупності) проміжку між елементами; порівняємо із вищевказаним
, середній розмір (для сукупності) проміжку між елементами; порівняємо із вищевказаним  .
.
Максимум вибірки є оцінкою максимальної правдоподібності для максимуму сукупності, але, як зазначалося вище, він є зміщеним.
Якщо вибірка не представлена числами, але її можна промаркувати або розрізнити, розмір популяції можливо визначити методом "Зловити/повторити".
Для будь-якого цілого числа m такого що k ≤ m ≤ N, імовірність того, що вибірковий максимум буде дорівнювати m можна розрахувати наступним чином. Кількість різних груп із k танків, які можуть бути утворені із загальної кількості з N танків визначається через біноміальний коефіцієнт  . Оскільки при такому способі підрахунку, перестановки танків розраховуються лише раз, ми можемо впорядкувати серійні номери і відмітити максимальний з них в кожній вибірці. Аби розрахувати імовірність ми повинні полічити кількість впорядкованих вибірок, які можуть містити останній елемент, який буде дорівнювати m а всі інші k-1 танків мають номери менші або такий що дорівнює m-1. Кількість таких вибірок з k-1 танків які можна отримати із загальної кількості m-1 танків задається біноміальним коефіцієнтом
. Оскільки при такому способі підрахунку, перестановки танків розраховуються лише раз, ми можемо впорядкувати серійні номери і відмітити максимальний з них в кожній вибірці. Аби розрахувати імовірність ми повинні полічити кількість впорядкованих вибірок, які можуть містити останній елемент, який буде дорівнювати m а всі інші k-1 танків мають номери менші або такий що дорівнює m-1. Кількість таких вибірок з k-1 танків які можна отримати із загальної кількості m-1 танків задається біноміальним коефіцієнтом  , тож імовірність отримати максимум m становить
, тож імовірність отримати максимум m становить  .
.
Дано загальну кількість N і розмір вибірки k, математичне сподівання максимуму вибірки визначається як:
![{\displaystyle {\begin{aligned}\mu =\mathrm {E} [m]&=\sum _{m=k}^{N}m{\frac {\tbinom {m-1}{k-1}}{\tbinom {N}{k}}}\\&={\frac {1}{(k-1)!{\tbinom {N}{k}}}}\sum _{m=k}^{N}{\frac {m!}{(m-k)!}}\\&={\frac {k!}{(k-1)!{\tbinom {N}{k}}}}\sum _{m=k}^{N}{\tbinom {m}{k}}\\&=k{\frac {\tbinom {N+1}{k+1}}{\tbinom {N}{k}}}\\&={\frac {k(N+1)}{k+1}},\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/23170ba302df742e8614d7cf4399c48636828c06)
де було використано рівняння із трикутником Паскаля[en]  .
.
Із цього рівняння, невідому кількість N можна розрахувати через сподівання і розмір вибірки, наступним чином

Відповідно до лінійності математичного сподівання, отримаємо
![{\displaystyle {\begin{aligned}\mu \left(1+k^{-1}\right)-1&=\mathrm {E} \left[m\left(1+k^{-1}\right)-1\right],\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6726c1a12f893fd011a31b3f4ef85ed8fde67da)
і таким чином незміщена оцінка для N отримується за допомогою заміни сподівання на спостереження,

Крім того, що ця оцінка є незміщеною вона також досягає мінімальної дисперсії. Аби показати це, відмітимо спершу, що максимум вибірки є достатньою статистикою для визначення максимуму сукупності, оскільки імовірність P(m;N) задається як функція лише від однієї m. Далі необхідно довести, що статистика m також є повною статистикою[en], особливим видом достатньої статистики (demonstration pending). Тоді Теорема Лемана-Шеффе[en] передбачає, що  є незміщеною оцінкою для N із найменшою дисперсією.[2]
є незміщеною оцінкою для N із найменшою дисперсією.[2]
Дисперсія оцінки розраховується як дисперсія вибіркового максимуму
![{\displaystyle {\begin{aligned}\mathrm {Var} [{\hat {N}}]&={\frac {(k+1)^{2}}{k^{2}}}\mathrm {Var} [m].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d8fa69e9a1c6a8afb1ed7eed054d6711657a8ea)
Дисперсія максимуму в свою чергу розраховується із математичних сподівань  і
і  . Розрахунок математичного сподівання для є наступним,
. Розрахунок математичного сподівання для є наступним,
![{\displaystyle {\begin{aligned}\mathrm {E} [m^{2}]&=\sum _{m=k}^{N}m^{2}{\frac {\tbinom {m-1}{k-1}}{\tbinom {N}{k}}}\\&={\frac {1}{(k-1)!{\tbinom {N}{k}}}}\sum _{m=k}^{N}m{\frac {m!}{(m-k)!}}\\&={\frac {1}{(k-1)!{\tbinom {N}{k}}}}\sum _{m=k}^{N}(m+1-1){\frac {m!}{(m-k)!}}\\&={\frac {1}{(k-1)!{\tbinom {N}{k}}}}\sum _{m=k}^{N}{\frac {(m+1)!}{(m-k)!}}-{\frac {1}{(k-1)!{\tbinom {N}{k}}}}\sum _{m=k}^{N}{\frac {m!}{(m-k)!}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/badb7b87eae8e7ab0aba1a5e655e967caaab25bf)
де другий терм є математичним сподіванням для . Перший терм можна виразити через k і N,

де була використана заміна  і використане рівняння із трикутником Паскаля[en]. Підставлення цього результату і математичного сподівання в рівняння для
і використане рівняння із трикутником Паскаля[en]. Підставлення цього результату і математичного сподівання в рівняння для ![{\displaystyle E[m^{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/04b8b1fb5c2054708e5f835ab5ae0d0ffe985ff5) дає
дає
![{\displaystyle {\begin{aligned}\mathrm {E} [m^{2}]&={\frac {k(N+2)(N+1)}{(k+2)}}-{\frac {k(N+1)}{k+1}}\\&=k(N+1){\Big (}{\frac {N+2}{k+2}}-{\frac {1}{k+1}}{\Big )}\\&={\frac {k(N+1)(kN+k+N)}{(k+1)(k+2)}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/236f18aacd1f9000a132377bfc24ab34a6ee9c5b)
Тоді можна отримати дисперсію для ,
![{\displaystyle {\begin{aligned}\mathrm {Var} [m]&=\mathrm {E} [m^{2}]-\mathrm {E} [m]^{2}\\&={\frac {k(N+1)}{(k+1)}}{\Big (}{\frac {kN+k+N}{k+2}}-{\frac {k(N+1)}{k+1}}{\Big )}\\&={\frac {k(N+1)}{(k+1)}}{\frac {(N-k)}{(k+2)(k+1)}}\\&={\frac {k(N+1)(N-k)}{(k+1)^{2}(k+2)}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c6db7102699fb7a2357727ad9b1cdb44f3c4d2a8)
Зрештою можна розрахувати дисперсію для оцінки ,
![{\displaystyle {\begin{aligned}\mathrm {Var} [{\hat {N}}]&={\frac {(k+1)^{2}}{k^{2}}}\mathrm {Var} [m]\\&={\frac {(k+1)^{2}}{k^{2}}}{\frac {k(N+1)(N-k)}{(k+1)^{2}(k+2)}}\\&={\frac {(N+1)(N-k)}{k(k+2)}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d27de49b7ad0676141e8d5d2300850e434053419)
- ↑ а б Johnson, Roger (1994), Estimating the Size of a Population, Teaching Statistics, 16 (2 (Summer)), doi:10.1111/j.1467-9639.1994.tb00688.x, архів оригіналу за 26 травня 2009, процитовано 18 березня 2019
- ↑ G. A. Young and R. L Smith (2005) Essentials of Statistical Inference, Cambridge University Press, Cambridge, UK, p. 95
|
|---|
| | | Дискретні одновимірні
зі скінченним носієм |
|
|---|
| Дискретні одновимірні
з нескінченним носієм |
|
|---|
| Неперервні одновимірні
з носієм
на обмеженому проміжку |
|
|---|
| Неперервні одновимірні
з носієм на напів-нескінченному
проміжку |
|
|---|
| Неперервні одновимірні
з носієм на всій дійсній прямій |
|
|---|
| Неперервні одновимірні
з носієм змінного типу |
|
|---|
| Змішані
неперервно-дискретні
одновимірні |
|
|---|
| | Багатовимірні (спільні) |
|
|---|
| | Напрямкові |
|
|---|
| | Вироджені та сингулярні[en] |
|
|---|
| | Сімейства |
|
|---|
|

